
様々な資料がここにあります。
DOCUMENTS
COMMAND
FORUM
UEC DOCS
VIDEO
様々な資料がここにあります。
DOCUMENTS
COMMAND
FORUM
UEC DOCS
VIDEO
全国にチェーン展開しているスーパーマーケットの運営本部に、各店舗から集められた売上データがあり、その中から特定の一週間についての売上を集計した帳票を作り分析に利用するというモデルケースを想定する。Open usp Tukubai※1を使って帳票を作成する。
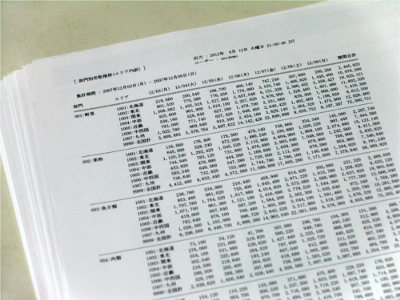
入力データおよび出力データはすべてスペース区切りのUTF-8テキストファイル(フィールド形式)で構成される。データベースは使わない。詳しい説明はUSP MAGAZINE Vol.5を参照のこと※2。
ターミナルの幅を120文字以上に変更したうえで、ダウンロードしたファイルの中に含まれているBUMONTRENDを実行する。集計および帳票テキストの作成が開始され、しばらくすると帳票が表示される。
パイプを多段につなげて処理するというプログラムの性質上、論理CPUの数が多いほど早く帳票が作成される。バックグラウンドで動かしながら、top(1)やps(1)でプロセス状況を監視すれば、データが一連のパイプの先頭に書かれたコマンドから順次処理されていることがわかる。
Linux top(1)コマンドはcを、FreeBSD top(1)ではaをタイプすることでコマンド引数を表示させることができる。FreeBSD ps(1)はオプションdでプロセスの親子関係をツリー状態にして表示させることができる。ps auxwwdといった使い方をする。
#!/bin/bash
# 変数の定義
tmp=tmp
start=20071203
end=20071209
#####################################################################
# 販売データの集計
# URE 1.店コード 2.商品コード 3.日付 4.売数 5.売上高 6.値引高
# BUMON 1.商品コード 2.部門コード
# TENAREA 1.店コード 2.エリアコード
# AREANAME 1.エリアコード 2.エリア名
# BNAME 1.部門コード 2.部門名
#####################################################################
awk '$3>='$start'&&$3<='$end'{print}' URE |
join1 key=2 BUMON |
sort -k1,1 |
join1 key=1 TENAREA |
# [LAYOUT] 1.店コード 2.エリアコード 3.商品コード 4:部門コード
# 5.日付 6.売数 7.売上高 8.値引高
self 4 2 5 6 |
# [LAYOUT] 1.部門コード 2.エリアコード 3.日付 4.売数
sort -k1,3 |
sm2 1 3 4 4 |
sort -k2,2 |
join1 key=2 AREANAME |
sort -k1,1 |
join1 key=1 BNAME |
# [LAYOUT] 1.部門コード 2.部門名 3.エリアコード 4.エリア名 5.日付 6.売数
awk '{print $1":"$2,$3":"$4,$5,$6}' |
# [LAYOUT] 1.部門コード:部門名 2.エリアコード:エリア名 3.日付 4.売数
yobi -j 3 |
awk '{$3=$3"("$4")";print}' |
delf 4 |
# [LAYOUT] 1.部門コード:部門名 2.エリアコード:エリア名 3.日付(曜日) 4.売数
# map : 部門/エリア単位に売数を日付横展開
map num=2 |
# awk : ヘッダー行を月/日(曜日)の形に加工
awk 'NR==1{for(i=3;i<=NF;i++){$i=substr($i,5,2)"/"substr($i,7)};print}
NR>1{print}' |
# ysum : 期間合計を付加する
ysum +h num=2 |
# sm4 : 部門ごとの合計行を挿入する
sm4 +h 1 1 2 2 3 NF |
awk '{if($2~/@/){$2="9999:全国計"};print}' |
# awk : ヘッダー行の編集
awk 'NR==1{$1="部門";$2="エリア";$NF="期間合計";print}
NR>1{print}' |
comma +h 3/NF |
# awk : 部門ごとに罫線を挿入する
awk 'BEGIN{k=sprintf("%0118d",0);gsub("0","=",k);}
NR<=2{print;if(NR==1){print k;gsub("=","-",k);}f=$1;}
NR>2{if($1!=f){f=$1;print k;}else if($1==f){f=$1;$1="@";}print;}
END{print k;}' |
keta -16 -12 10xNF-3 11 |
tr '@' ' ' > $tmp-body
# ヘッダーをつくる
y1=$(echo $start | cut -b 1-4)
m1=$(echo $start | cut -b 5-6)
d1=$(echo $start | cut -b 7-8)
w1=$(yobi -dj $start)
y2=$(echo $end | cut -b 1-4)
m2=$(echo $end | cut -b 5-6)
d2=$(echo $end | cut -b 7-8)
w2=$(yobi -dj $end)
cat << END > $tmp-header
[ 部門別売数推移(エリア内訳) ] 出力 : $(date)
ユーザー : $USER
集計期間 : ${y1}年${m1}月${d1}日(${w1}) - ${y2}年${m2}月${d2}日(${w2})
END
# ヘッダーとデータを合わせて出力
cat $tmp-header $tmp-body
# 終了
rm -f $tmp-*
exit 0
プログラム BUMONTREND
1001 北海道 1002 東北 1003 関東 1004 中部 1005 近畿 1006 中四国 1007 九州
データファイル AREANAME
001 野菜 002 果物 003 魚介類 004 肉類 005 調味料 006 乾物その他 007 米 008 和風冷蔵 009 菓子 010 飲料 011 酒類
データファイル BNAME
0000007 001 0000017 001 0000021 002 0000025 002 0000027 001 0000030 001 0000043 001 0000045 002 0000047 001 0000048 001 0000053 001 ...略...
データファイル BUMON
0001 1003 0002 1005 0003 1003 0004 1007 0005 1002 0006 1005 0007 1003 0008 1005 0009 1003 0010 1006 ...略...
データファイル TENAREA
0001 0000007 20071201 117 8335 -145 0001 0000007 20071202 100 7821 -130 0001 0000007 20071203 103 6012 -115 0001 0000007 20071204 104 6341 -120 0001 0000007 20071205 102 6165 -135 0001 0000007 20071206 106 7201 -125 0001 0000007 20071207 108 6033 -115 0001 0000007 20071208 132 6106 -100 0001 0000007 20071209 127 7437 -105 0001 0000007 20071210 113 6299 -115 ...略...
データファイル URE
プログラムBUMONTRENDは帳票の本体作成部分とタイトル作成部分とに分けられる。特に注目すべきは帳票の作成部分。すべてがパイプに収まっている。パイプを構成するコマンドは25個。
もっとも最初に処理されるのが売上データを収めたUREファイルのデータ。投入される際、まずawk(1)にかけられ、処理対象期間の行だけが抽出される。次に商品コードとそれが所属する部門を紐付ける部門マスター表(BUMON)が結合され、データを整列したのち、店コードと所在地域を紐付けるマスター表(TENAREA)と結合されている。
このように「売上データに何か付け足したり削ったり」を一連のパイプで実施しており、最終的に出力されるデータは目的とする帳票そのものとなる。Open usp Tukubaiが準拠しているユニケージ開発手法は、このようにデータありきの設計スタイルをとるのがひとつの特徴といえる。
※ ユニケージはユニバーサル・シェル・プログラミング研究所の登録商標。
※ usp Tukubaiはユニバーサル・シェル・プログラミング研究所の登録商標。
※1 Open usp Tukubaiは最新バージョンを採用のこと。古いバージョンでは適切に動作しない可能性がある。
※2 USP MAGAZINE Vol.5より加筆修正後転載。
※3 本ページで公開されているプログラムとそれに付随するデータの著作権およびライセンスは、特に断りがない限りOpen usp Tukubai本体と同じMITライセンスに準拠するものとする。