
様々な資料がここにあります。
DOCUMENTS
COMMAND
FORUM
UEC DOCS
VIDEO
様々な資料がここにあります。
DOCUMENTS
COMMAND
FORUM
UEC DOCS
VIDEO
シェルスクリプトではコマンドの入出力をパイプで接続することで処理を実施する。特にユニケージ開発手法ではパイプによるデータの連続処理を重要視しており、パイプの性能は処理に大きな影響を与えている。
商用版のusp Tukubaiコマンド群はコマンド内部で自律的な最適化が実施されており、パイプで接続された場合に性能が期待できるようになっている。しかしこの機能は商用版のusp Tukubaiコマンドを使わずとも、dd(1)コマンドを組み合わせることでも実現できる。通常、こうした高速化のテクニックは「ダブルバッファ」と呼ばれる。
たとえば次のようなコマンドを想定する。特定のファイルシステムのバックアップを丸ごと実施するようなコマンドだ。
$ dump /usr | bzip2 > backup.bz
dumpの実行をssh(1)経由にすれば、遠隔のマシンから自動的にバックアップを実施し、バックアップデータを特定のマシンに集約するといった操作を実施できる。運用向けのコマンドである。
ダブルバッファは基本的に次のようにdd(1)コマンドを挟み込むことで実現する。
$ dump /usr | dd bs=サイズ | dd bs=サイズ | bzip2 > backup.bz
1つ目のdd(1)が最初のコマンドが出力するデータをある程度溜め込むための第1バッファ、2つ目のdd(1)が次のコマンドに最適化されたデータサイズで送信するための第2バッファとなる。
第2バッファでは次のコマンドがもっとも高速に処理できるサイズ単位でデータを送り出すようにする。このサイズはマシンやOS、利用するソフトウェアによって異なる。たとえば今回のケースでは、次のようなシェルスクリプトを作成して、どのバッファサイズが最もbzip2(1)が高速に動作できるのかを調査することで探ることができる。
#!/usr/local/bin/zsh
for i in 1 2 4 8 16 32 64 128 256 512 1024 \
2048 4096 8192 16384 32768 65536 \
131072 262144 524288 1048576
do
echo $i
count=$((2097152 / $i))
{ dd if=/dev/urandom bs=$i count=$count |
time bzip2 -9 > /dev/null; } |& tail -2
done
ここで重要なのはディスクIOを発生させない点にある。このスクリプトではdd(1)で/dev/urandomからデータを取り出すことで、ディスクIOを発生させることなくbzip2(1)の処理速度を模索している。
シェルスクリプトの出力をグラフに整理すると次のようになる。処理速度が最速かつプロセッサ占有率が最も高い中から、もっともバッファサイズが小さいものを選択する。今回の例では16バイトまでほぼリニアに性能がスケールし、以後は2KBあたりを頂点にして緩やかに性能があがり、以降は劣化するという特性になっていることがわかる。今回のケースでは第2バッファは2KBにすれば良さそうということになる。
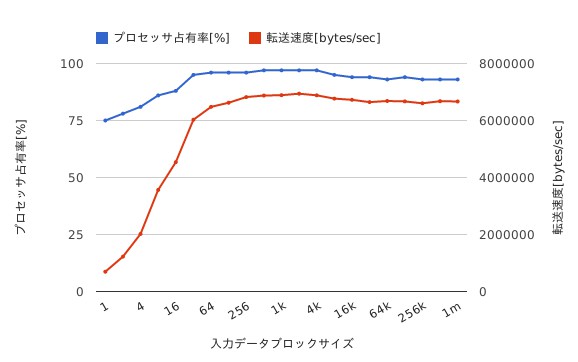
第1バッファは最初のコマンドの出力をある程度貯めこむ処理を実施する。最初のコマンドの出力が遅い場合や、出力速度が一定ではない場合などは、特にこのバッファサイズを大きくしてやる必要がある。逆に、一定的に、しかも高速にデータが出力される場合には、第1バッファのサイズは小さくなる。
第1バッファのサイズを変更しながら処理速度を比較するスクリプトを次のように作成して計測する。
#!/usr/local/bin/zsh fs=/usr echo no double-buffer (time sh -c "dump -f - $fs 2> /dev/null | bzip2 -9 > backup.bz") |& grep total echo single-buffer (time sh -c "dump -f - $fs 2> /dev/null | dd bs=2k | bzip2 -9 > backup.bz") |& grep total for i in 2k 4k 8k 16k 32k 64k 128k 256k 512k 1m 2m 4m 8m 16m do echo $i (time sh -c "dump -f - $fs 2> /dev/null | dd bs=$i | dd bs=2k | bzip2 -9 > backup.bz") |& grep total done
シェルスクリプトの出力結果をグラフに整理すると次のようになる。
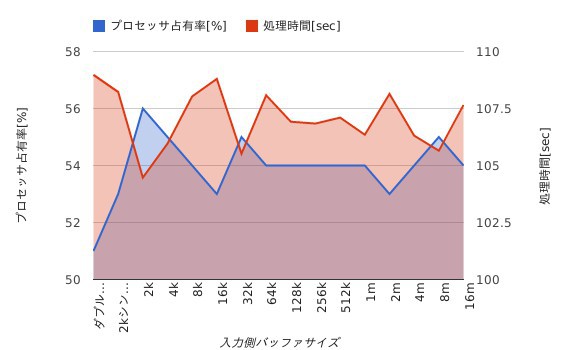
あまりリニアな結果は得られないが、バッファを挟んだ方が処理速度が高速化していること、シングルバッファよりもダブルバッファの方が性能が期待できること、第1バッファは2KB、4KB、32KB、8MBあたりでスポット的に性能が期待できること、などが見て取れる。
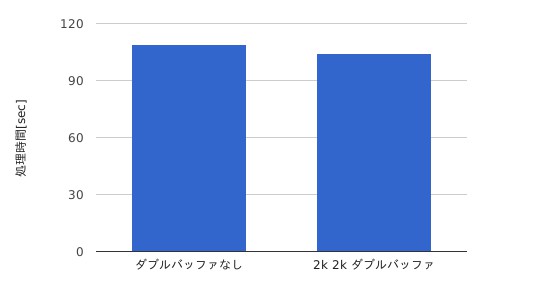
今回のケースではもっとも性能が良かったのは第1バッファが2KB、第2バッファが2KBの時となり、大体4%ほど高速化できたことになる。dd(1)を挟み込むだけで処理の高速化が実現できたことになる。たとえば24時間かかるような処理であれば、dd(1)を挟み込むだけで1時間ほど処理時間を短縮できることになる。
ここに示した結果ではあまり大きな変化は見られないが、ディスクIOの性能が遅いマシンであったり、ネットワークごしのデータ転送が挟まるケース、またはプロセッサの性能が低いマシンなどでは、この「ダブルバッファ」の手法を使うことで大幅な性能向上が期待できる。
マルチコア/マルチプロセス化が進む傾向にあるため、こうしたダブルバッファの手法はコアの性能を使い切る上でも効果が期待できる。今後のシェルスクリプトプログラミングを実施する上で覚えておきたいテクニックだ。
なお、闇雲にバッファサイズを変更しても期待した結果は得られないことが多い。第2バッファおよび第1バッファのサイズを定量的に計測して効果が期待できるバッファサイズを調査してから利用する必要がある。
※ usp Tukubaiはユニバーサル・シェル・プログラミング研究所の登録商標。