
様々な資料がここにあります。
DOCUMENTS
COMMAND
FORUM
UEC DOCS
VIDEO
様々な資料がここにあります。
DOCUMENTS
COMMAND
FORUM
UEC DOCS
VIDEO
ユニケージとは、ソフトウェアにおける1つの型である。そこにはどんな作法があり、どんな理があるのか。これまで口伝によって伝えられてきた作法を今、文章として残す。今回は、ユニケージ流の徹底したデータ保存方法について伝える。
日本には博物館や美術館と呼ばれる施設が多数存在する。国や自治体が運営しているものから、中小企業や個人が街中で運営しているもまで大小様々だ。
これらは観光施設として捉えられがちだが、真の存在理由は別のところにある。長い年月を掛け試行錯誤の末に先人達が導き出した結論(物体、文書など様々)を、後人が短時間で得られるようにするためである。もし、ある分野の博物館が消滅したらどうなるだろう。人類は1つの英知を失い、再び長年かけた試行錯誤からの出発を余儀なくされてしまう。観光施設としての一面には、英知を後世に遺すための維持費を募る意味があるのだ。
さて、ユニケージエンジニアの作法には、このような博物館・美術館的な思想を持つものがある。各時期、各場所で生み出されたデータを、貴重な文化遺産であるかのように捉え、少々手間や費用が掛かっても、しっかり保存するというものである。なぜ、このような作法が生まれたのだろうか。
「バックアップは取っておけ」とは、コンピューターを扱う者なら誰しも口を酸っぱくして言われることだ。そして筆者を含め、それを怠ったがゆえに苦い経験をしてきた人は多いことだろう。
しかし、ユニケージエンジニアの「バックアップ」は特に徹底している。バックアップをとるというよりは、生じたデータを消さないと表現する方が相応しいのかもしれない。
1つの例を挙げよう。
ある量販店において、日々刻々と増減し変化する商品名、価格などの商品データを一括管理するプログラムがあったとする。このプログラムはまず、大元の商品データファイルを持っている。また、到来した商品データの追加・削除・変更要求をその都度ログファイルへと出力する。更に、商品データの項目をどのように並べるかといった情報や、商品データファイルやログをどこに置くかといった、情報を定義する設定ファイルがあるものとする。
さてこの時、何を保存すべきだろうか。商品データファイル、ログファイル、設定ファイル、さらにはプログラムファイル、これらの最新版を保存しておくことは必須だろう。そうしておけば、システムが載っているディスクドライブが壊れても復旧ができる。
だが、それで安心とはいえない。もし「最近の商品データは何だかおかしい」と指摘を受けてしまった時は、最新版の複製があっても役に立たない。「そんな時のために、バージョン管理システムがある」と思うかもしれない。ではバージョン管理システムのおかげで最新バージョンの欠陥が明らかになり、すぐさま直せたとする。しかし、本来あるべき今日の正しい商品データファイルはどうやって作ればいいのだろうか。商品名の変更や削除という要求もあったはずだから、最新の商品データファイルがあったところで、正しかった時点まで巻き戻すことは不可能だ。それでも、すべて保存されているログファイルに基づき、一番最初から追加・変更・削除の作業をやり直せばよいと思うかもしれない。だがそれが長年運用してきたシステムだったとしたら……、気の遠くなるような作業になる。
このような事態は避けたいものだ。そこでユニケージエンジニアは、「その日」のファイルを毎日保存するためのシェルスクリプトを作る。その日の商品データファイル、その日のログファイル、その日の設定ファイル。更にはその日のプログラムファイル一式、また必要とあらばその日のOSの設定ファイルまで、必要なものはすべて保存する。こうして、「その日」をシステム運用の歴史として遺すのである。
「残す」ではなく「遺す」すという字を選んだのは、「後の世代のためにやる」という意味を強調したいからだ。
しかし、いくらなんでもやり過ぎではないかと思うかもしれない。追加・変更・削除要求の記録されたログファイルは毎日違うものだから異論はないであろうが、商品データファイルや設定ファイルなどは、その内容の大半が前日のものと重複する。年末年始で休業している時期があるとすれば、その期間は毎日まったく同じ内容になるかもしれない。そんな冗長さを許してまで、何も考えずに保存するというのか、と。
だが、そのとおりなのである。むしろ「何も考えない」ことこそが重要だ。何も考えずに保存するということは、後に必要になった時も何も考えずに取り出すことができるということである。必要になった時というのは大抵、障害対応などで切羽詰っているはずだ。そのような状況下の人の、考えさせられる時間を増やしては「後世のために遺す」の本質が薄れてしまう。
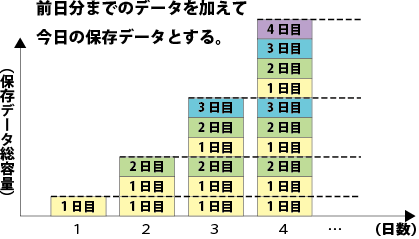
従って、データを保存するにあたっては、後の運用者が無駄に考えないで済むような形で行うことが重要だ。
トランザクション系データの中には、日付ではないもの(たとえば商品番号)順に並べることに意味があるものがある。そういったものは、日付で区切らず、ずっと1つのファイルに書き出す方が取り扱いに便利ということになる。もしデータの増分が毎日一定だとすると、このファイルについての「その日」を毎日保存する場合、等差数列の和になって保存ファイル全体の容量は、二次関数的に増えていくことになる。それでも何も考えず保存するというのだろうか。
そのとおりだ。ファイルが分割されていないことに意味があるのであれば、分割しないまま保存すべきである。確かに取引発生日毎に分割して保存すれば容量は日数に比例して増えるに留まるだろう。しかしそうすると、切羽詰っているであろう後の運用者にファイルの復元(結合)という作業を強いることになってしまう。避けたいのはそこなのである。
次のシェルスクリプトを見てもらいたい。これはユニケージエンジニアが実際の現場で用いているデータ保存用のシェルスクリプトを一部抜粋したものである。
#!/bin/sh # 昨日のデータに対し、今日のtransactionを追記し、 # 今日のデータを作る # (データのフィールド構成) # 1:担当者コード 2:担当者名前 3:担当者カナ # 4:所属部署 5:所属課 6:備考 # 7:表示フラグ 8:並び順 9:削除フラグ # 10:登録時刻 11:登録担当者コード today=$(date '+%Y%m%d') # 今日の日付 yday=$(mdate $today/-1) # 昨日の日付 datd=/PATH/TO/THE/DATA/DIR # データ保管場所 echo $inpd/OPERATOR/OPERATOR.$today*.*.sem | tarr | sed 's/\.sem$//' | xargs cat | # ごみ掃除 awk 'NF==11' | # 登録時刻とキーでソートする LANG=C sort -k1,1 -k10,10 | # 今日のtransactionを優先して昨日のデータに挿入 up3 key=1 $datd/OPERATOR/OPERATOR.$yday - | # 同一内容で登録時刻だけ違うレコードを削除 getlast 1 9 \ > $datd/OPERATOR/OPERATOR.$today.new
このプログラムが保存しようとしているデータは、とあるシステムのトランザクションデータである。元のデータファイルは、担当者毎、かつ日付毎に個別に存在している。このシステムではデータ取扱上の理由で、それらのファイルをすべて一ファイルにまとめ、担当者コード順にソートした状態で保存することになっている。
そこでこのプログラムでは、始めのecho~xargs catの行で当日のトランザクションファイルをすべて開き、その後のsort行で担当者コードの順番を最優先にソートし、up3コマンドの行に送っている。up3行では運用開始から前日までのすべてのトランザクションがファイルとの結合を行っている。up3とはTukubaiコマンドの一種であり、今注目している列(この例では担当者コード行)の順番を崩さずに2つのファイルを結合する。たとえば、左側の引数として指定されたファイルに担当者A、B、Cの行が10行ずつあり、右側のファイルにも同様にA、B、Cが1行ずつあったとすれば、この右側のA、B、Cはそれぞれ、左側ファイルの10行目と11行目の間、20行目と21行目の間、30行目の後に挿入される形で結合される。
注目すべきは、このプログラムの最後に書き出されたファイルが翌日にup3の結合材料として使われることである。これはつまり、一日に処理するデータ量が日数に比例して増加していくと共に、保存しているデータの総容量は二次関数的に増加していくことになる。
ここで気になるのは、そんなことを許してしてシステムは破綻しないのかということであろう。しかしほとんどの場合、心配には及ばない。UNIXコマンドもTukubaiコマンド(ビジネス版)も単純なCで実装されており、扱うデータも先頭から順番に読むだけでよいテキストファイルになっていて、元々が軽いうえに、コンピューターの処理速度向上の速さが驚異的であるので、意外なほど短時間で終わる。実際、ある現場では504万行のデータをこのシェルスクリプトにかけるとIntel Xeon E5-2600搭載のコンピューターでわずか4秒しかかからないという。
データ容量に関しても、後述する工夫と組み合わせればほとんど問題にならない。とても極端な例を挙げて考えてみよう。1,000店舗を誇る大手小売店があり、1店舗あたり日平均300人が来店するとする。客1人が会計をすると80Bytesのトランザクションデータが発生し、これを先程のやり方(本日ファイル=前日ファイル+本日データ)で保存したとして、5年後の総容量はどれ程になるだろうか。試算すると約27TBである。今の時代、それほど非現実的な数字でもないはずだ。もちろん、実際にはもう少し工夫をするのだが、そうしなかったとしても、この規模の業者のシステム復旧にかける費用を鑑みれば、決して高い備えとは言えないだろう。
前回の作法で「さじ加減」と伝えたばかりであるが、今回の作法においてもそれは重要である。肝心なことは、後の運用者に無用な苦労を強いないことであるから、苦労を極力掛けないような配慮をしながら工夫をする。
まずはファイルの圧縮。gzip等有名な形式を利用しておけば、流石に解凍の方法で頭を悩ませる運用者はいないだろう。gzipは本件で扱うようなテキストデータに対しては概ね元の1/10まで容量を減らすことができる。
次に検討すべきは、一定以上の過去データの整理である。確率論的に考えれば、データが整理されたことによって後の運用者に及ぼす苦労の度合いは、それが過去のデータであるほど小さいといえる。そこでたとえば、一カ月前までの商品データは全日保存、それ以降三年前までは月始めのものだけ残し(必要とあらば取引データログから希望日の商品データを復元)、三年以上経過したものは削除する、といった具合だ。
先程の1,000店舗の小売業者の例も、データをgzip(1)などのツールで圧縮保存し、200日より前に生成したデータを消す(この場合でも各日のファイルには運用開始日からのデータが残る)ものとして再度試算すれば1TBに収まる。
このような工夫を採り入れ、実際の現場で利用されているコードを再現してみたものが次のシェルスクリプトである。詳しい説明は省略するが、プログラムが生成したデータやログファイルの他、プログラム一式、さらには定期的にプログラムを実行するためのcrontab(5)のデータも保存している。ただし、この例では、原形のままの保存期間は3日間、あるいは7日間と定め、それ以降のファイルは圧縮したり削除したりするようになっている。一部にTukubaiコマンドを用いているが、全体的に見渡せばさまざまな現場でよく見かけるシェルスクリプトであり、特殊なことは何もしていない。
#!/bin/sh
tmp=/tmp/$0.$$ # 一時fileのprefix
logd=/PATH/TO/THE/LOG/DIR # log保管場所
datd=/PATH/TO/THE/DATA/DIR # データ保管場所
bakd=/PATH/TO/THE/BACKUP/DIR # backup先
HOSTNAME=$(hostname) # ホスト名
today=$(date '+%Y%m%d') # 今日の日付
# 1) LOG整理、7日以上前のfileと"UPCNT"を圧縮し、
# 7日以上前のファイルを削除
mkdir -p $bakd/LOG
#
find $logd -name 'LOG.*' -type f -ctime +7 > $tmp-loglist
echo $logd/UPCNT |
cat $tmp-loglist - |
xargs tar -rpf $bakd/LOG/LOGBACKUP.$HOSTNAME.$todayhms.tar
#
gzip -f $bakd/LOG/LOGBACKUP.$HOSTNAME.$todayhms.tar
cat $tmp-loglist |
xargs rm -f
# 2) cronのバックアップの保存
mkdir -p $bakd/CRONTAB
crontab -l |
gzip > $bakd/CRONTAB/CRONBACKUP.$HOSTNAME.$todayhms.gz
# 3) シェル関係を一括圧縮
mkdir -p $bakd/SHELL
( echo $home/*/{CGI,HTML,SHELL,TEMPLATE,IMAGE,INPUT,OUTPUT}/*
echo $home/SYS/*
echo $home/public_html/* ) |
tarr |
# ヒットしなかったecho行の削除
sed '/\*/d' |
# 元々がバックアップのものは対象外
sed '/BACKUP/d' |
xargs tar -rpf $bakd/SHELL/SHELLBACKUP.$HOSTNAME.$todayhms.tar
gzip -f $bakd/SHELL/SHELLBACKUP.$HOSTNAME.$todayhms.tar
# 4) 3日前のfileを圧縮し、7日前のfileを削除
y3day=$(mdate $today/-3)
y7day=$(mdate $today/-7)
if [ -d $datd ]; then
cd $datd
for dir in *; do
if [ -d $datd/$dir ]; then
gzip -f $datd/$dir/$dir.$y3day
rm -f $datd/$dir/$dir.$y7day.gz
fi
done
fi
なぜこれほどまでに多大な冗長さを許しながら、毎日「その日」のデータを遺すのか。そのもっとも根本的な理由は、ここまでの手間や費用を掛けても尚、障害発生時に抑えられる手間や費用の方が大きいと試算されるからである。
エンジニアは、とかく無駄の削減や効率の向上を強く意識し、無駄なく最高の効率で稼働するシステム開発に労力を費やしがちである。またはそこに美しさを見い出そうともする。しかしコンピューターの性能向上の勢いは目覚ましい。「そんなことをしたら性能が伸び悩む」と懸念していた仕様が、今のコンピューターを以ってすれば実運用上、すでに議論に値しない問題となっていることも珍しくない。
マイク・ガンカーズが説くUNIX哲学の1つに「効率よりも移植性」という定理がある。つまりプログラムにおける効率は、必ずしも最優先とすべきではないということだ。ユニケージ開発手法も、根底にある思想は同じである。プログラムの効率追求に囚われないからこそ、生まれた作法と言えよう。
USP MAGAZINE summer 2013 松浦智之著、「第七回 ユニケージエンジニアの作法」より加筆修正後転載